[BigData] "달에 쓰는 일기": 일기 데이터로 단어 빈도 추출하기
빅데이터 시간에 워드 클라우드도 배웠고,,, 갑자기 내 일기 데이터로도 해보고싶어졌다.
나는 달에 쓰는 일기라는 어플로 매일매일 일기를 쓰는 편이다.
2018년 4월부터 쭉 써왔으니...몇년이여 5년쯤 쓴듯.
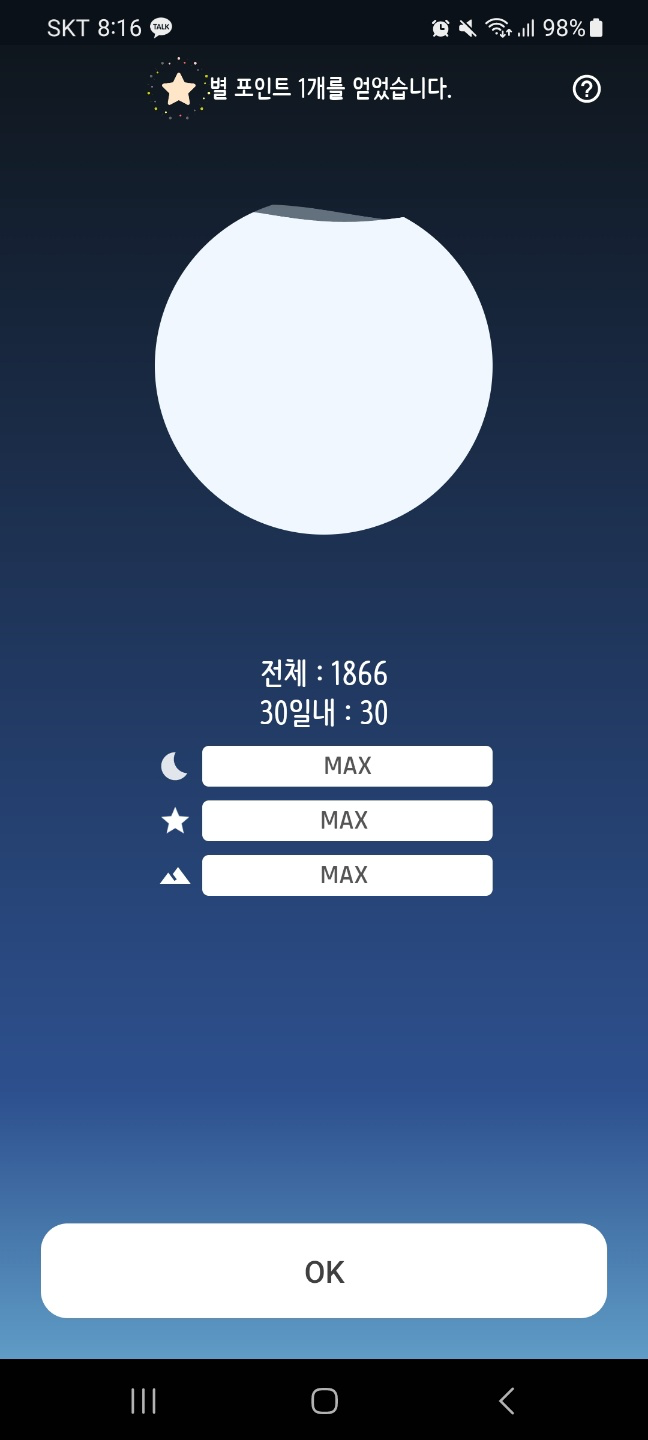
지금까지 1866개의 일기를 써왔다고 한다.
(앱 바꾸기 귀찮아서 쭉 써온 건데 이렇게 활용할 날이 오다니...)
이 데이터로 단어 빈도 분석 가보자구~~~!!
먼저 이 일기 데이터를 파일화 해야한다.
달에 쓰는 일기 앱>설정>일기 백업하기: 텍스트 파일로 저장하기
이렇게 하면 txt 파일 하나를 얻을 수 있다!

1930장...ㄷㄷㄷ 짱이다 뿌듯해
이제 코드를 작성해보자.
나는 jupyter 환경에서 작성했다.
먼저 코드 짤 때 필요한 라이브러리들 모두 선언
# 텍스트 빈도 분석
import json
import re
from konlpy.tag import Okt
from collections import Counter
import matplotlib
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
from wordcloud import WordCloud
from nltk.tokenize import word_tokenize
파일을 읽어봅시다
# 파일 읽기
file_path = '/Users/min0/Documents/Documents/school/4-1/빅데이터/과제/diary.txt'
data = open(file_path, 'r')
data출력은 다음과 같다

그 담엔 이 파일의 데이터들을 년도별로 담아보자.
데이터를 담을 때 필요없는 특수문자는 전부 제외해주었더. 나는 !!!!나 ??!? 이런 걸 엄청 썼기 때문에...ㅎㅎ
# 분석할 데이터 담기
text2018 = ''
text2019 = ''
text2020 = ''
text2021 = ''
text2022 = ''
text2023 = ''
while True:
line2018 = data.readline()
if line2018[:4] == "2019": break
else: text2018 = text2018 + re.sub('[-=+,#/\?:^.@*\"※~ㆍ!』‘|\(\)\[\]`\'…》\”\“\’·]', '', line2018)
while True:
line2019 = data.readline()
if line2019[:4] == "2020": break
else: text2019 = text2019 + re.sub('[-=+,#/\?:^.@*\"※~ㆍ!』‘|\(\)\[\]`\'…》\”\“\’·]', '', line2019)
while True:
line2020 = data.readline()
if line2020[:4] == "2021": break
else: text2020 = text2020 + re.sub('[-=+,#/\?:^.@*\"※~ㆍ!』‘|\(\)\[\]`\'…》\”\“\’·]', '', line2020)
while True:
line2021 = data.readline()
if line2021[:4] == "2022": break
else: text2021 = text2021 + re.sub('[-=+,#/\?:^.@*\"※~ㆍ!』‘|\(\)\[\]`\'…》\”\“\’·]', '', line2021)
while True:
line2022 = data.readline()
if line2022[:4] == "2023": break
else: text2022 = text2022 + re.sub('[-=+,#/\?:^.@*\"※~ㆍ!』‘|\(\)\[\]`\'…》\”\“\’·]', '', line2022)
while True:
line2023 = data.readline()
if not line2023: break
else: text2023 = text2023 + re.sub('[-=+,#/\?:^.@*\"※~ㆍ!』‘|\(\)\[\]`\'…》\”\“\’·]', '', line2023)
print("2018: ", len(text2018))
print("2019: ", len(text2019))
print("2020: ", len(text2020))
print("2021: ", len(text2021))
print("2022: ", len(text2022))
print("2023: ", len(text2023))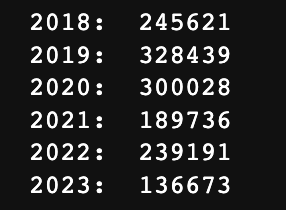
이제 필요 없는 단어들을 쳐내야 한다.
이를 위해 필요 없는 단어 문자열을 만들어준다.
일단 기본적으로 전부 쳐낼 문자열을 만들고,
stop_words = "오감 아침 점심 저녁 오늘 내일 하루 다행 어제 진짜 모닝 오후 오전 아침 정말 보고 이제 그냥 다시 그거 지금 계속 뭔가 고민 조금"년도별로도 쳐낼 문자열들이 있어서 따로 만들어줬다.
이 과정을 불용어를 제거한다고 한다.
stop_words2018 = "글구 잠깐 거리 누구 애가 내내 등등 다그 와우 이도 사이 일이 자서 는걸 하자 쪼끔 학년 가면 대서"
이제 단어화 후 불용어 제거를 거친다.
이 단어들의 빈도수를 계산하고, 빈도수가 가장 높은 단어들을 골라낸다.
# 2018 단어 빈도 분석
# 명사 추출
message_N2018 = nlp.nouns(text2018)
# 불용어 제거
temp = [word for word in message_N2018 if not word in stop_words]
result2018 = [word for word in temp if not word in stop_words2018]
# 단어 빈도 계산
count2018 = Counter(result2018)
# 빈도 높은 단어 계산
word_count2018 = dict()
for tag, counts in count2018.most_common(250):
if(len(str(tag))>1):
word_count2018[tag] = counts
print("%s : %d" % (tag, counts))
출력물은,,,비밀임ㅋ
이제 이를 워드 클라우드를 사용해서 출력해보자!!
나는 맥 환경이라 맥 환경에 맞게 폰트를 설정해줬다.
wc = WordCloud(font_path='/System/Library/Fonts/Supplemental/AppleGothic.ttf', background_color='ivory', width=800, height=600)
cloud2018 = wc.generate_from_frequencies(word_count2018)
plt.rcParams['font.family'] = 'AppleGothic'
plt.figure(figsize=(8,8))
plt.title("2018: 고3")
plt.imshow(cloud2018)
plt.axis('off')
plt.show()
그럼 이렇게 나온다....ㅎㅎ

나머지 년도들도 같은 과정을 거쳐주면 된다.
친구 이름 개많이 나와서 다 지움
암튼 일기에 많이 쓴 단어 분석하기 짱 쉽져
18~23년도 전부 분석해봤는데...
년도별로 확확 틀려지는 단어들이 재밌었다...
18이 고3때였는데 이때 친구들 이름이 잔뜩 있고,
대학교 갈수록 친구들 이름이 줄어들고,,, '강의', '교수', '공부' 이런 단어들이 워드 클라우드의 대부분을 차지한다..ㅋㅋ씁슬
올해 반년정도 남은 동안 더 재밌게 살아서 다채로운 단어들을 만들어야겠다,,ㅎ.ㅎ